With our experience and expertise on Pure Language processing we have now developed few functions which has impression on particular buyer use case.
We’ve got solved downside utilizing Pure language processing as under:
- Spam filters examine.
- Optical Character recognition.
- Grammar examine
- Laboratory report examine
- Textual content Clustering – To fetch outcome.
Right here we try to clarify NLP utilizing textual content dataset enter and outcome output based mostly on textual content.
As per the chosen knowledge codecs, know-how corporations create clustering algorithms that additional generate clusters. These corporations should first create and convert textual content knowledge right into a digital matrix format as per the obtainable knowledge. As a prime app growth & IT software program firm, we had to make use of data retrieval methods TF–IDF (time period frequency-inverse doc frequency) in one in all our NLP-based resolution initiatives.
The answer had to decide on classes of the 12 months which may auto-select the thought among the many all. We labored on the reply to create primary clusters based mostly on repetitive key phrases and kinds of key phrases. Additionally, we divided the sub-clusters based mostly on the principle teams. Nevertheless, we additional analyzed the size of the offered dataset or through which class it’s effectively positioned.
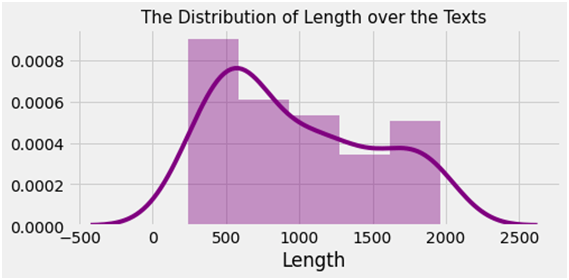
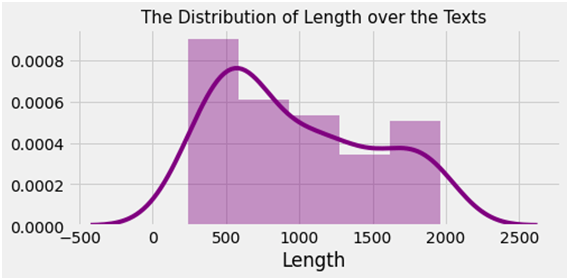
Fig. Distribution of size over the textual content
TF-IDF is a numerical statistic that exactly displays how vital a phrase is to a doc in a set or corpus. The TF-IDF worth boosts proportionally to the variety of instances a phrase seems within the doc and is offset by the variety of information proper within the corpus that accommodates the phrase, which assists in adjusting for the truth that some phrases seem extra usually.
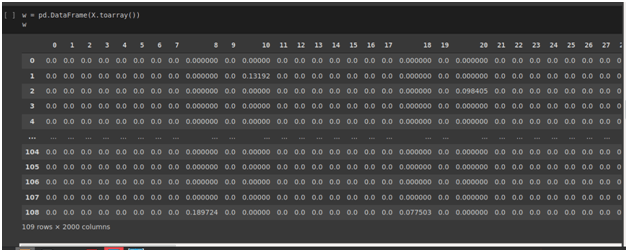
Fig. Digital corpus was created with the assistance of TF-IDF (time period frequency-inverse doc frequency).
With the info in hand, there have been some impurities that we addressed within the mission. The impurities included Decrease Casing, Elimination of Punctuations, Cease-word elimination, Widespread phrase elimination, and different textual content knowledge preprocessing. Via the bar chart, we additionally analyzed that some phrases had been repeated and had extra occurrences within the dataset.
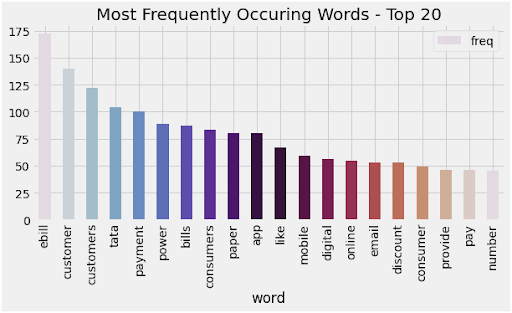
Use of Clustering Algorithm
With clustering, we grouped a set of objects in order that the cluster objects are extra related to one another than these in various clusters. We divided the inhabitants or knowledge factors into a number of teams, like knowledge factors in the identical teams, much like different knowledge factors in the identical group than these in different teams. The intention was to segregate teams with related traits and assign them into clusters.
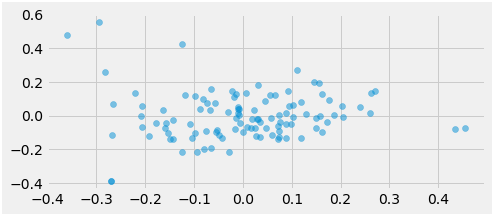
Fig: entries earlier than clustering
We used Ok-means clustering for the above dataset, a vector quantization technique, from sign processing with the target to partition n observations proper into the okay clusters. Every commentary exactly belongs to the cluster and with the closest imply serving as a prototype of the cluster.
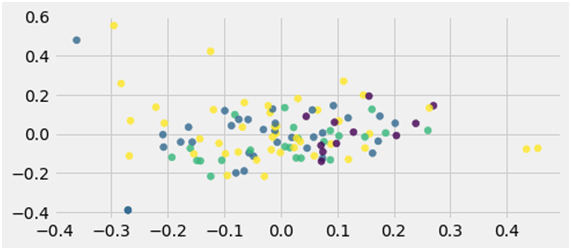
Fig: entries after making use of Ok-means clustering algorithm
Software of Clusters Illustration
For displaying clusters, we utilized the D3.js collapsible tree construction within the mission. D3.js is a exact JavaScript library used for manipulating paperwork that are based mostly on knowledge. D3 assists you to carry knowledge to life utilizing HTML, SVG, and CSS. D3 emphasizes internet requirements and affords you the entire capabilities of recent browsers with out tying your self to a proprietary framework. It blends highly effective visualization elements, and takes a data-driven method to DOM manipulation.
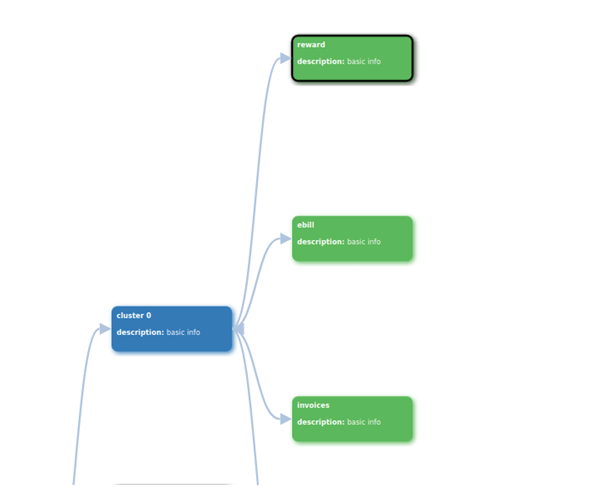
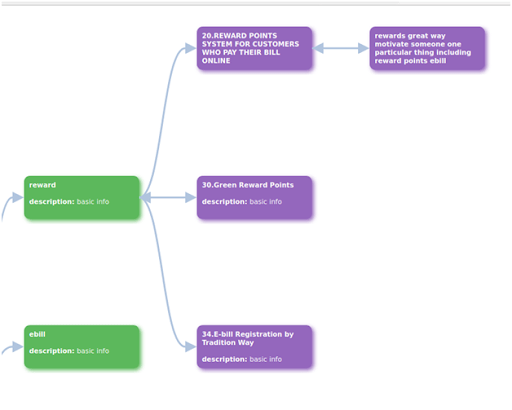
Fig: Tree construction of clusters
By analyzing the above tree construction, we will say that each cluster has sure phrases that provide extra weightage. In cluster 0, we have now three phrases, that are rewards, ebill, and invoices. After we click on on one of many phrases, the subsequent cell is populated with an thought listing. This collapsible tree will probably be extraordinarily useful for thought administration. We will add extra element for thought description in extra cells. The design and construction of the above collapsible tree construction might be reworked as per the necessities.